Microservices are great architecture for various IT areas. It supports the successes of many organizations, but on the other hand is often subject to quite strong criticism. How to avoid possible problems and properly use the mechanisms provided by microservices?
Each microservice independent
Each microservice, as a module, should be as independent as possible. And on many levels. From a communication perspective, it would be best, if its operation did not depend, especially synchronously, on other microservices. It should be delivered as a separate distribution module, should work in a separate process, use its own and exclusive database. It is also particularly important, that each module should be independently developed in the context of work organization, business and technology.

What are the advantages of this approach? Development independence minimizes the time to make changes. No extensive analysis is needed, there are fewer agreements and decisions are made at a lower level. Interprocess communication and separate databases allow to avoid overly tight coupling of individual components, i.e. situations when, as a result of changes in one module, changes in the associated modules also prove necessary.
However, the independence of microservices is not an end in itself. Misunderstood can hinder cooperation between components and slow down the development of the whole system. Properly implemented, it stands behind most of the benefits offered by microservices. Problems with its implementation are the way to classical microservices antipatterns, such as distributed monolith.
Let's try to look at various aspects of microservices' independence.
Separate databases
The basis for the correct microservices is the independence of the data structures they use. The lack of this independence is the reason for many problems occurring during the growth of monolithic application.
If we had several modules working on common data (in the same table), any change, e.g. to the table structure, would mean the need to coordinate and simultaneously change all places, that use this data. To maintain the ability to change quickly, we must avoid this.
Advantages
- The possibility of independent development of each module – including a complete change in its implementation, if necessary.
- Avoiding problems of tight coupling – changes in the data structure (in one table) of a given module do not require analysis and potential changes in other modules.
Disadvantages
- Each microservice holds its own data separately, so some of them overlap and duplicate.
- Risk of data consistency loss – each module keeps its own copies and communication between them occurs in a vulnerable, distributed environment.
- Maintaining full data consistency is complicated – it requires the use of dedicated design patterns, such as Eventual Consistency, SAGA, CQRS or Event Sourcing.
Design autonomy
Design autonomy, also called decentralized management, is an approach, where the way, in which a given business functionality is implemented in a microservice, is decided independently by the team dealing with a given module.
Advantages
- Decentralized management is important for speeding up implementation and delivery of changes, due to the reduction of arrangements between teams.
- Offers benefits related to quality of work and well–defined responsibility. The team feels that its decisions and work are clearly linked to the final solution and its value.
Disadvantages
- The risk of conceptual drift, especially at the API level that each module provides – for example, trouble, if we use the same term to describe different objects.
- The tendency to limit API documentation and description of how a given functionality works.
- Risk of neglecting some cross–sectional requirements or treating them in a different way – security, logs, configuration, data validation, error handling, support for monitoring and other production tools.
- Scattered information about the overall architecture of the solution.
- Distribution of responsibility, in the case of complex business processes, consisting of calls of many functions in different microservices.
Guidelines
- The concepts used across the system should be clearly and precisely defined.
- The API should be described clearly and using consistent terminology. This also applies to the format of individual fields – such data as amount, currency, phone number, address can cause many problems when formats differ.
- The ease of maintaining and making changes also depends on some framework imposed on the solution – architectural consistency is a value, not just a limitation.
- Even with independently managed microservices, someone needs to comprehensively understand both processes and business requirements, as well as the architecture of the entire system.
- In our opinion, the design independence of modules should be used with caution, with periodic reviews, and with maintaining and communicating the vision of the entire solution in the organization.
Using the right technology for the job
Design independence in a given microservice allows for using the technology, that best suits a specific task.
Advantages
- Eliminates the problems with long–term binding of the solution to the technological stack.
- Allows for a complete change of the microservice implementation technology, if needed.
- Cost optimization at the level of development – we can take advantage of external software and new possibilities it offers.
- Thanks to the possibility of using the latest solutions, potential improvement of performance, safety and efficiency of the solution itself.
- Facilitates the construction of certain business processes that cannot be implemented without the use of dedicated technologies (e.g. AI).
- Does not create significant difficulties in delivery and production maintenance.
Disadvantages
- Risk of technology becoming too fragmented – this increases costs and makes it difficult to maintain the solution (although the use of containers – e.g. Docker – reduces these difficulties).
- Many dependencies in software can effectively slow down development and, paradoxically, impede changes.
- Many technologies also add an extra cost to acquiring and maintaining distributed team competencies.
Guidelines
- Try to keep the golden mean. Let's take care about the consistency of the solution – it allows for many savings and reduces the risk of errors. Let's assess whether the new technology will give us real benefits on an order of magnitude level or just a few percent. With small benefits it is not worth losing the consistency of the solution. If the benefits are significant, let's use the opportunity, that microservices give us and apply the implementation method that best suits the requirements.
Independent deployment
The independence of the microservice also means the ability to prepare the deployment on its own, i.e. assemble all operations, from code approval, testing, quality assessment, preparation of delivery resources, packing them in appropriate containers, integration with subsequent environments, to production rollout.
Advantages
- No need for detailed coordination of deployments with other teams definitely facilitates and accelerates the introduction of changes.
- The risk of change in a single module is low. Faster release verification on production and, if necessary, a short return time to the previous solution version.
Disadvantages
- A large number of separate distribution modules means that dedicated automation tools must be used.
- Investment is needed to build and maintain an appropriate delivery process.
- Initially, changes to delivery processes can be met with considerable resistance. Many teams have to change their way of working.
The possibility of independent deployment is a major value. And in general, one of the main benefits of microservices’ architecture. Independent deployment is possible due to the autonomy and small size of individual modules. Achieving the appropriate quality of this process is, however, quite a challenge in any organization.
Microservices loosely coupled
One of the basic assumptions of microservices is the loose coupling of services. In this respect, it is about making sure that the individual modules depend on each other as little as possible. We discussed the advantages and disadvantages of various types of independence above and in the previous article (especially in relation to the division of the system into modules). At this point, we will try to focus on how to avoid too tight coupling (because the degree of coupling can vary), especially in the context of coupling at runtime – that is, in communication between components.
In the extensive microservice system, there are a lot of interactions between dozens or hundreds of modules. The method of communication between them can be different. Both messages exchanged online as well as integration through queues or event streams are acceptable. Below we will briefly present the different models of communication between the modules.
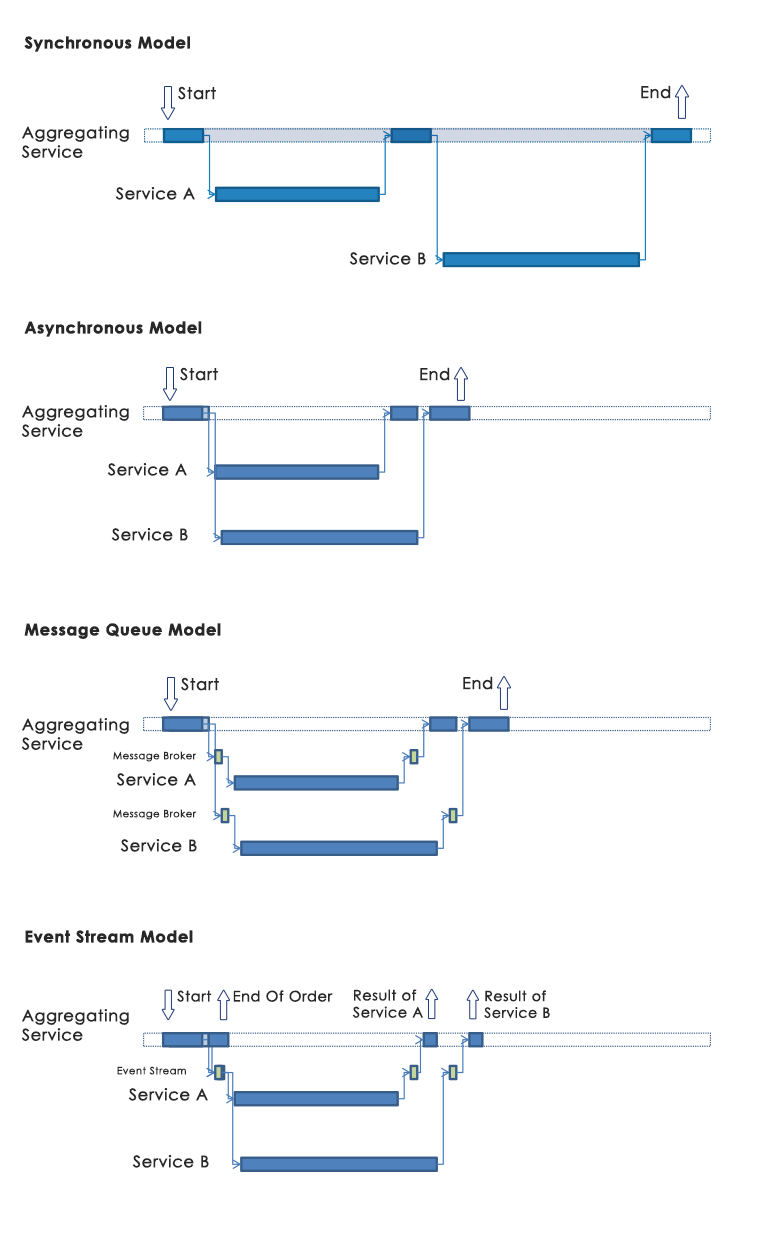
Synchronous communication
Synchronous online communication is most common for microservices. It is the easiest to implement, it also allows for an intuitive reflection of the business process and duplicates the mechanisms usually used on the frontend – e.g. HTTP protocol. The calling module transmits the request message and, while maintaining the connection, waits for an answer. During this time the business process is suspended.
Unfortunately, such an option does not give full independence. The unavailability of one service will generate the unavailability of services using it. What's more, failure of one service may generate cascading problems of resource depletion (e.g. thread pool) at higher levels. Of course, this risk can be reduced and such failures can be dealt with – many design patterns are addressed to this problem, but it is an additional complication of the solution.
Asynchronous communication
To reduce the problems encountered in synchronous communication, another model of online communication is often used – asynchronous processing. This is an interesting approach, similar to the synchronous model, with the difference that the process or thread supporting a given function does not wait idly for an answer while calling another service, but can handle other orders during this time. When the response arrives, it will be able to deal with it, but does not reserve resources (e.g. threads or connections to the database) until the response arrives. Thanks to the fact that we do not wait blockingly for an answer, we can order work to be done in other microservices in parallel and not one after another. This speeds up the execution of a given business function.
In the asynchronous model it is also easier to avoid the cascade use of resources in case of slowdown or failure of one service, and we can handle a much larger number of parallel connections.
One of the disadvantages of this model is a little more complicated implementation than in the synchronous model. It should also be remembered, that most often, this model assumes waiting for a response, limited by timeout, so still the unavailability of the target service will result in the unavailability of a higher level service. Asynchronously written module is able to handle multiple connections in parallel, which means, that it is not difficult to accidentally overload the target system.
Communication via message queue
Another model, with even more loose coupling of the modules, is the communication by passing messages from the producer to the consumer through the queue system. In this model, the individual services are indeed more independent of each other – they know themselves, but the consumer does not have to be available at a time, when the producer is generating message. However, the availability of the Message Broker during that time is necessary.
Whether or not, depending on the availability of the message consumer, the business process will stop or not depends on how the process is defined. Usually a function call is initiated by someone, who is waiting for its outcome (e.g. a client). For him, if the message consumer is unavailable, a response will not be generated, i.e. the service will still be down. It should also be remembered, that communication in the queue model is subject to a certain delay, while the advantage is that, there is no risk of overloading the message consumers, because they retrieve data from the queue with their own performance.
Communication via event stream
A model similar to communication via queues, but the message is not addressed to a specific recipient (or recipients). Instead, individual modules deal with the production and consumption of events. An event is not a message – it is not sent to a specific recipient. In principle, a given event does not have to be consumed by any recipient at all. In fact, producers and consumers don't need to know anything about themselves.
The business process itself is also subject to some abstraction – it does not have to be controlled by any dedicated component, it can only indirectly arise from the complex process of production and consumption of events by various microservices. This gives great flexibility, but at the cost of losing the transparency of the business process.
From the point of view of the work independence of individual components, the event model is the most loosely coupled approach. We have no problem here, that the failure of one component affects the operation of others. It is necessary to have, though, the event stream handling module (e.g. Kafka), but individual microservices decide about the pace and logic of their work.
Unfortunately, this approach also means risks arising from data duplication and their parallel operation – we do not have a good way to ensure continuous data consistency in such a model. Usually, the eventual consistency approach is used in such a case, i.e. we allow for the situation, that the data in different modules may temporarily not be consistent. To handle complex business processes, where individual events can generate errors during processing, compensating transactions and the SAGA model are used.
In the event approach, it is possible to define the user interface in such a way, that a positive message means only accepting the order for service, not executing it. The effect of this order does not have to be visible immediately. It may appear with some delay. A similar approach should also be used by external systems, with which the event system integrates. Unfortunately, this increases the complexity of the solution.
How to reduce the degree of coupling?
- Avoid the integration of modules based on a database – it is a source of errors and gradually, as the system develops, slows down work on it.
- Appropriate division into microservices – to avoid the need for simultaneous changes in many modules.
- Service API’s based on business abstractions, independent of the method of internal implementation – allows you to change the implementation of the module without affecting systems communicating with it.
- Functions provided in a manner consistent with the system's standards – these are both communication protocols, as well as certain usage conventions and naming schemes. In such a situation, external systems are easier to integrate without the need for special arrangements between teams.
- The exact specification of services is very important – it is in fact a contract between the module offering the given function and the modules using it. As above, it simplifies the communication and avoids the so–called side effects.
- The most loosely coupled microservices are provided by a model based on integration through an event stream, but we recommend caution, when it comes to complexity and control over the business process.
- Different communication models can coexist. Depending on the type of microservice and the characteristics of its operation, different ways of integration can be adopted – so as to balance the cost resulting from the complication and the effect we want to achieve.
- Regardless of the way the components are connected, it is necessary to ensure resilience to communication errors.
End of the second part.
Hava a look at Part3 Meeting objectives