When to assume that we have software ready to work in the cloud? How to build systems dedicated to the cloud, which mechanisms and processes should we implement to be able to state that our system will be a good cloud system?
When is the solution cloud-based?
Each system deployed as a part of cloud services can nominally be called Cloud. However, it is a certain simplification. If we take typical software built to work in a private server room and move it to the cloud, it will not change the characteristics of its operation. A truly cloud-based solution should enable us to fully take advantage of the abilities of the cloud and properly handle the challenges that accompany it. Simply moving the software to an external service will not, unfortunately, ensure this.
Moreover, talking about cloud services should not be limited to the applications themselves as programs to run. Adapting a solution to the cloud can and should also mean investing in building mechanisms supporting work in the cloud - from work organization, through the manufacturing process to handling the production environment.
Native cloud services
Depending on the model of cloud location (private, public, branch or hybrid) and its service type (IaaS, PaaS, SaaS, etc), we can speak about very different technologies. Additionally, the area of cloud solutions is constantly growing and changing. In this article we will try to present a reference model of a cloud solution. In order to do this, we will use the term cloud native. To facilitate the discussion and promote good practice in the area of cloud services, the term was defined by CNCF foundation (Cloud Native Computing Foundation - www.cncf.io) and is commonly used nowadays.
At first, let’s quote CNCF definition:
„Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.”1
[1] DEFINITION.md on github/cncf
To elaborate on this definition a bit more, the point is not only that the application is designed in such a way that it works well in the cloud, i.e. its architecture is based on loosely connected microservices and is relies on clearly defined APIs, but also that its integration and deployment model allows for frequent and easy code updates, that administrators have tools to monitor and manage the platform, that we have mechanisms to ensure scalability, load balancing and fault tolerance.
The native cloud solution can take full advantage of the cloud from software development to production work, and this means building a full production process (from writing a code, through testing, integration, deployment, monitoring, infrastructure supervision, security mechanisms, accountability and much more).
When we already have software which works, while adjusting it to the cloud we should pay attention to whether it can be efficiently located in any model of cloud services (private, public or other). It must also be able to work independently of specific configurations of a particular server, but it should be adapted to the requirements of the platform controller (e.g. Kubernetes). It should also be divided into small, freely scalable modules, loosely connected with one another. What’s more, particular modules should allow for far-reaching automation, which means using, i.e. containers and suitable CI/CD (Continuous Integration / Continuous Delivery) tools.
While preparing running software to the cloud, we should pay attention to whether it can be efficiently deployed in any model of cloud services (private, public, other). It must also be able to work independently of specific configurations of a particular server, but it should be adaptable to the specific requirements of the controller of a given platform (e.g. Kubernetes). It should also be divided into small, freely scalable modules, loosely coupled to each other; individual modules should allow for far-reaching automation, which means, among other things, using containers and appropriate CI/CD (Continuous Integration / Continuous Delivery) tools.
Support areas for cloud services
Describing cloud services, we can point out a few main areas in which using suitable tools and mechanisms allows for successful implementation and fully native operation in the cloud.
 Native Cloud Support Areas: Contenerization, Microservices, Orchestration, DevOps + ServiceMesh, Agile
Native Cloud Support Areas: Contenerization, Microservices, Orchestration, DevOps + ServiceMesh, AgileContainerization
Containerization is a way of defining a given system as a set of independent, small distribution units. Each of such units may contain applications, processes, configuration and other necessary elements, so that a given container is as independent as possible. This facilitates independent development and transfer of software between different operating environments (e.g. as a part of scaling).
Container technology, however, is not dedicated only to the application distribution process. It also allows for running, isolated from infrastructure, particular modules on the same operating system (OS). The memory, network connections and disk space are isolated, which makes the mechanism similar to virtual machine (VM). However, the isolation is not complete here – it takes place on the level of the same OS instance, which results in particular modules (in different containers) dynamically sharing the same resources (e.g. CPU).
The advantage of the mechanism of containers is less performance overhead than in the case of full virtualization. It is not necessary to translate every calling between virtual and real CPU, and it doesn’t have to go through many intermediate layers. An additional benefit of containers is much shorter, than in case of virtual machines, time needed to start or stop instances of a particular application, , which makes it easier to scale and flexibly adapt individual modules of the solution to current needs.
Using open-source Docker software is currently the most popular form of containerization.
Microservices
Microservices is a model of system architecture based on cooperation of small and independent services. Individual microservices are oriented around business capabilities, work in separate processes and on separate data. They are loosely coupled with other microservices and communicate only through documented APIs (messages or events).
Every microservice, within a given application, can be delivered, updated and scaled independently. Due to a potentially big number of microservices, automated processes (CI&CD) are most often used here. Docker containers are particularly convenient as distribution and operating units for microservices.
Microservices model is often presented in opposition to the monolithic model, where:
- system software is delivered as a single distribution,
- changes require restart of the whole solution,
- modifications in one element may affect any other fragment of the solution,
- finally, as the systems ages, its development, scaling and maintenance cause more and more problems.
Microservices technology aims to overcome these problems. Development of independent services may be faster, because they are independent of each other. As long as the service interface is maintained, any changes, including technological ones, will not be noticeable by other components in the system. Developers can focus on the main functionality of their module, without having to analyze the whole solution every time.
Thanks to independent distribution, testing and automation of deployment, it is possible to update particular fragments of application without noticeably affecting the accessibility of business services to clients.
Every microservice can be run in any number of instances. It can be independently scaled and replicated. Such properties also allow for achieving high reliability and effective use of computing resources, which means generally efficient work of the whole system, too.
There is no single recommended technology in which microservices should be built. On the contrary, it is recommended not to tie in with one technology. It is important to keep the possibility to integrate and manage different services, that is, it’s necessary to have documented API and support assumptions made in the area of cross-cutting issues (e.g. security). However, platforms or programming languages may be different from one micro-service to another.
In microservices model, it is also frequently postulated to change work organization of the company. Instead of horizontal division into teams – where competences of every team concern its technical area of work, it is advisable to try to build teams vertically – in view of a business area. Such, vertically organized team can look after a particular microservice as a whole, on any technical level, eliminating communication barriers this way. The postulate of vertical organization is also connected with the use of Agile methodologies, where it is also important to improve communication and accelerate the software development and implementation cycle.
[EDIT] More about that architecture: Microservices – strengths and weaknesses
Orchestration
So, we already have software which works in containers and realizes its functionality in the form of microservices. This facilitates adapting to the load, makes deployment processes easier but also poses challenges related to the number of elements in a solution, where manual management of every element is no longer physically feasible.
This is where space is created for a special software - an orchestration platform for a container-based solution. The orchestration platform allows to manage, among others, such areas as configuration, container coordination, load balancing in a distributed, complex architecture, adjusting the scale of operation to the load. There exist many tools to achieve the above goals - e.g. Apache Mesos or Docker Swarm, but the most popular solution in this area is currently Kubernetes (also supported under OpenShift) and we will focus further description on it.
Kubernetes (K8s for short) was created as an internal Google project, currently it is an open-source platform managed by the CNCF foundation. It provides a framework for running container-based applications and provides the following functionalities:
- Name service for containers – allows to address components abstractly.
- Load balancing between instances of a particular service – to ensure maximum performance and stability of work.
- Automatic connection of data storages – so that individual containers can conveniently use local and cloud data stores.
- Automatic roll-out and roll-back – independently brings the environment to the declared form of components deployment, creating and removing containers according to needs.
- Adjustment of the usage of CPU and RAM resources – every container can declare how much CPU and RAM it needs; Kubernetes will adjust them to the infrastructure accessible at the moment.
- Self-healing – Kubernetes independently restarts and deletes containers, which do not pass tests for proper operation set by administrator.
- Secret and configuration management – Kubernetes allows to manage the configuration independently of specific containers, including sensitive and confidential data, such as passwords, tokens, SSH keys.
Kubernetes provides an additional layer of abstraction in relation to physical machines, networks and data stores. Instead of describing its structure and operation here, we will try to present the basic concepts of Kubernetes:
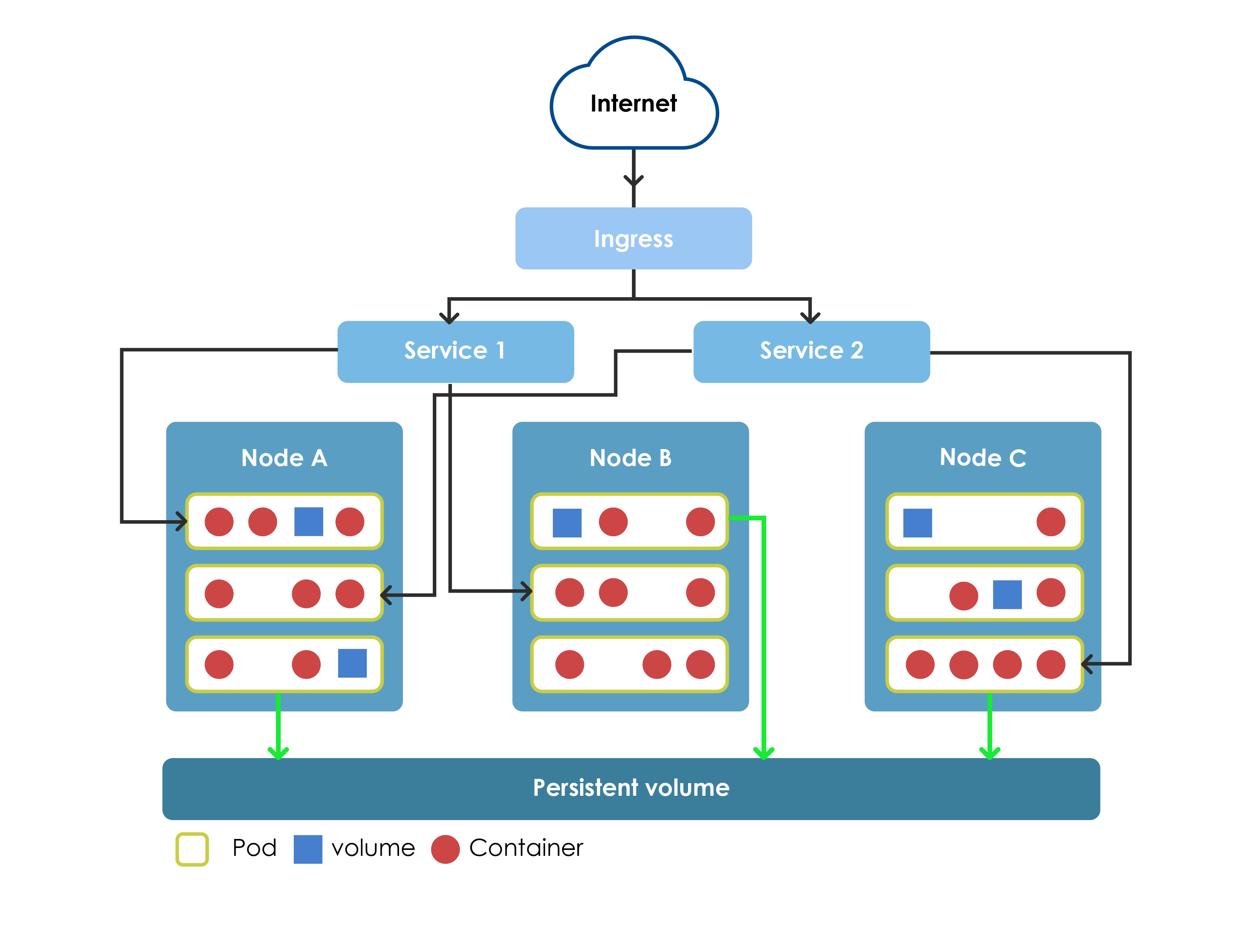 Kubernetes Modules Organization
Kubernetes Modules Organization- Nodes – physical or virtual machines running individual containerized applications.
- Pods – container groups logically linked to each other. Pods are run by Kubernetes on individual nodes according to the declarative environment description and are the basic element of scaling and load balancing. Containers within a Pod can share the data being processed; they can communicate locally over a network, but cannot directly see containers from other Pods.
- ReplicaSets – allows you to specify the set (number) of instances of a given Pod that should be available at the moment. The mechanism is also controlled by a higher level abstraction - Deployments, which provides the way to manage changes in relation to the number of instances of a particular Pod.
- StatefullSets – performs a similar function as ReplicaSet, allowing you to define instances of Pods, but it is used when individual Pods are not interchangeable. StatefullSets concept ensures ordered startup, permanent identification and numbering of every Pod, stable network identifiers and data stores. StatefullSets is used in a situation when particular instances differ from one another – e.g. when handling databases – where one is in Primary mode and the other in Secondary.
- DaemonSets – it allows to define Pods which are to be run in every Node in K8s cluster. When Nodes are added or removed, Kubernetes ensures that in every working Node there will be a Pod instance with DaemonSets.
- Services –logically named sets of Pods, providing their services on the network with load-balancing implemented by K8s mechanisms.
- Volumes – by default, within a given container, the file system is recreated again after each restart of the container, so you cannot permanently save data there. Kubernetes provides the Volume - data store, whose life cycle is not associated with the container, but with the Pod that stores it. Volumes can also be used to share data between different containers within a Pod.
- PersistentVolumes – because Volume abstraction is not fully permanent (because it is recreated after every restart of a Pod), Kubernetes also provides the concept of PersistentVolumes. Only this kind of data storage is permanent because it is connected with the whole cluster.
- ConfigMaps – configuration management mechanism. Kubernetes ensures that the configuration data related to a given Pod will reach all Nodes of a Cluster in which the Pod is started. This data will be accessible for all containers defined within the Pod. For security reasons, the configuration data is kept on each Node in the operating memory and available to individual containers as a file system or as environmental variables. Kubernetes also provides an API to manage such configuration and allows for changes in the running environment.
- Secrets – specific, sensitive configuration data such as passwords or access tokens. This type of data is specially protected by Kubernetes, however we must remember that it is not fully safe by default. In particular, data of this kind can be transmitted in a masked form as base64 encoded text (although the latest versions use encryption to store data).
- Ingress – K8s API object allowing access to the system from outside, usually in the form of HTTP proxy. Among other things, it can perform load-balancing and allow SSL termination. Proxy tools such as HAProxy, Envoy or nginx are used as Ingress controllers (Routes component plays a similar role within OpenShift).
- Helm – an additional tool for managing the description of application components - can be understood as Kubernetes package manager, where individual applications are defined in the form of so-called Charts - a configuration of a set of software resources (a similar role is played by OpenShift Templates).
Kubernetes is particularly well suited to microservices architecture. It provides loose coupling between components, allows to freely and independently scale individual applications. Kubernetes is not associated with any specific technologies, most of the modules are interchangeable and, on any level, you can choose between options available as open-source or commercial software, or create your own modules where applicable.
DevOps
DevOps is a set of practices in the IT area, which combines software development (Dev) with maintenance operations of a production solution (Ops). The aim of this methodology is to shorten the implementation cycle, ensuring high quality of solutions and continuous software delivery. The way to achieve these goals is such an approach to building systems or running products and services, which is based on cooperation, communication and integration of development and maintenance teams.
DevOps practice assumes using dedicated tools which facilitate achieving the goals of this methodology. These tools may fall into the following categories:
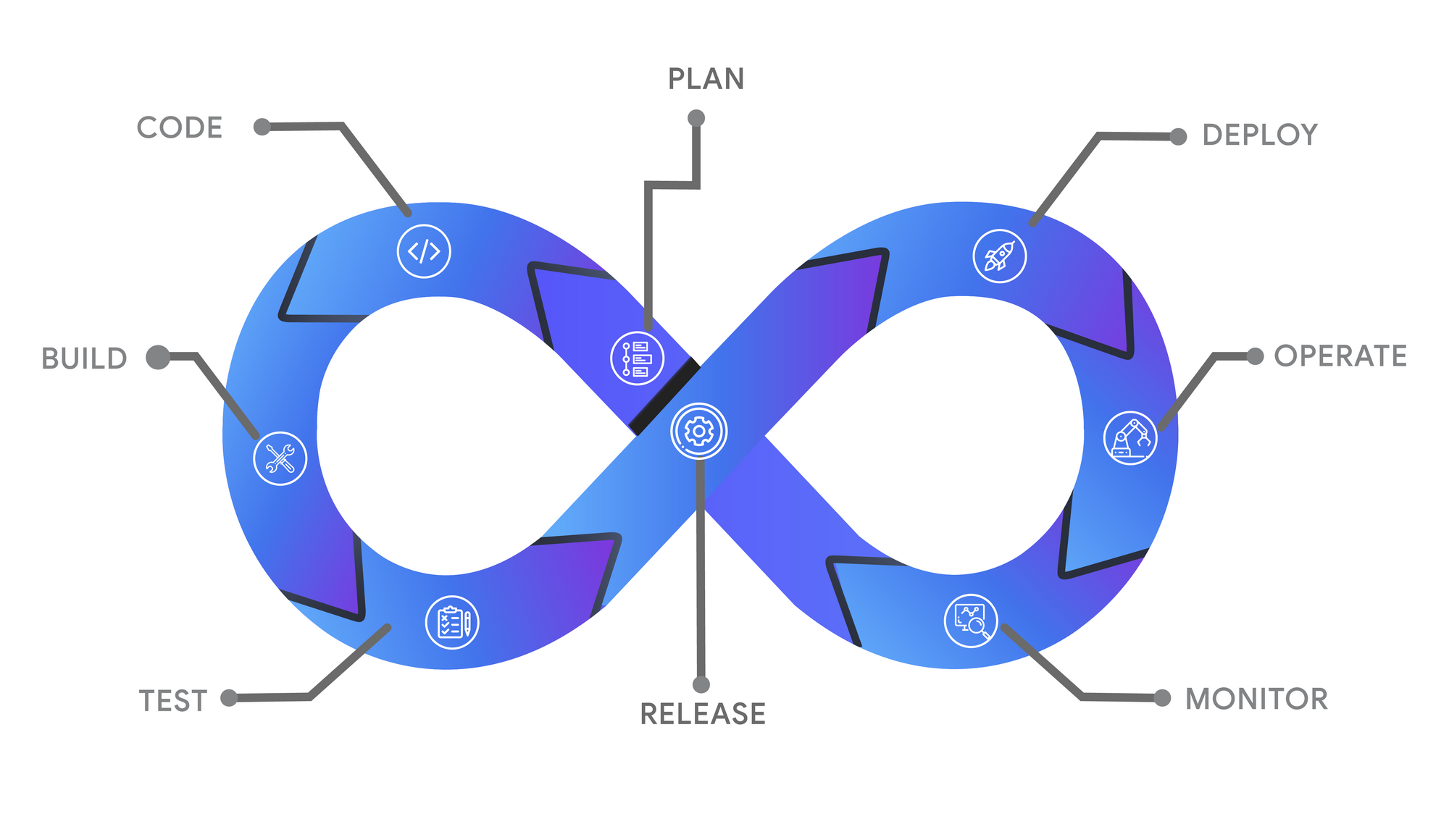 DevOps: Coding-Building-Testing-Release-Deploy-Operate-Monitor-Plan
DevOps: Coding-Building-Testing-Release-Deploy-Operate-Monitor-Plan- Coding– software development and verification, source code management tools (version control tools, including the mechanisms of merging different branches).
- Building – Continuous Integration tools, automation of builds – using build servers, creation of resources and distribution artifacts – including containers (e.g. Docker).
- Testing – Continuous Testing tools, automated tests support (at the level of developer and the whole distribution), software quality management, reporting of test results.
- Release – Continuous Delivery tools, transferring distribution packages, change management, release permission control, process automation, pre-production environments control.
- Deploy – Continuous Deployment tools, automation of code installation and activation, access management to production environments, version and upgrade process control.
- Operate – containers orchestration tools in a cluster (e.g. Kubernetes), Infrastructure As a Codetools (e.g. Ansible) – system configuration management, control of configuration changes related to updates, control of configuration consistency between nodes
- Monitor – tools for verifying operation and measuring application quality - in terms of access to logs (ELK/EFK tools - Elastic, Logstash/FluendDB, Kibana), performance monitoring (e.g. Prometheus, Grafana), tracing (e.g. Jaeger, Elastic APM, OpenTracing, Zipkin) and the effectiveness in meeting the end customer's needs.
- Plan – the information received during the realization of the former steps is to lead to conclusions regarding the preparation of subsequent changes in the software, on a continuous basis.
The term DevOps is often used with relation with the term CI/CD - Continuous Integration & Delivery/Deployment. In the Deliveryvariant, the product is to provide software ready to be deployed to production, in the Deployment variant, the effect of the process is already the production start-up. The CI/CD approach can be understood as a subset of the DevOps area. They use the same tools, e.g. Jenkins, Travis CI and many others.
DevOps is also often associated with the use of Agile methodologies as a complement. This is due to similar goals - improving communication, in the case of Agile between the client and developers, in the case of DevOps between developers and maintenance team. In both methodologies we have a high readiness for change, in both of them the goal is a short feedback loop - and therefore frequent rollouts and quality verification.
DevOps is basically necessary when working with a native cloud. A large number of containers, microservices, configuration resources, nodes in the infrastructure, combined with the expected fast deployment modes, basically excludes reliance on manual work. In order to ensure the quality of the whole solution, it is necessary to organize work based on automation and the use of appropriate tools.
Service Mesh
Service Mesh is an additional, optional element of the native cloud. In the native cloud model, a single application can consist of hundreds of services, each consisting of multiple containers and running in multiple instances on dozens of nodes. Additionally, orchestration tools, such as Kubernetes, dynamically distribute traffic, which makes the work environment constantly change. Ensuring continuity of communication between services is, in such a solution, a very complicated task, especially in terms of maintaining efficiency and reliability of work. Service Mesh software is the answer to these challenges.
Service Mesh is a certain, manageable, generating little delays layer of infrastructure. It offers efficient network communication between services shared within the application. This layer is responsible for the speed, reliability and security of communication, offering possibilities such as:
- extended services addressing catalogue,
- load balancing (on application layer – level 7, and non-transport – level 4, like in the case of the orchestrator itself),
- exchangeable transport protocol (e.g. TCP, HTTP/1.x, HTTP/2, gRPC),
- authentication and authorization of access at the level of individual services, encryption with mTLS and PKI certificates,
- dynamic traffic management (separated from infrastructure scaling, which the orchestrator does itself) – overload protection (fuse pattern – circuit breaker, bandwidth limiters, retry budgets), Blue/Green deployment, gradual introduction of new versions of services, including test versions – canary releases,
- support for solution resilience tests – fault injection at application level, generation of random delays,
- tools for telemetry analysis and tracing.
Technically, Service Mesh is a network of interconnected proxies, placed next to the application code within each instance (Pod) of all modules of the solution. By using the Sidecar design pattern, the application does not have to be aware of its work behind the proxy, or more generally, in the ServiceMesh model. The work of all proxies is managed from the in one place (the so-called Control Plane), where, in particular, the rules of traffic management are defined. The network communication between the services is carried out within the Data Plane. Thanks to such a model, all the above mentioned capabilities can be achieved independently of the construction technology of a given application, and all policy changes are available without the need to make corrections in individual modules.
Many different Service Mesh tools are available. On the basis of open-source solutions, we can also build our own mechanisms, adapted to individual needs. The most popular Service Mesh tools include Istio, Consul Connect and Linkerd.
Summing up
The above elements are a set of basic, main building blocks for a fully native cloud solution. However, it should be remembered that this is a reference set. On every level, different tools can be used to achieve the desired effect in a given application.
The described areas are also, of course, in no way a complete description of the cloud solution components - no mention was made of special cloud database versions, notification and event stream handling modules, dedicated cloud datastores, container repositories, configuration management tools and many other components often used in cloud solutions. These modules are also useful in the cloud, and sometimes even necessary depending on the solution, but the above article focuses on general-purpose modules.